深度学习教程 | 深度学习概论

作者:韩信子
教程地址:[www.showmeai.tech/tutorials/3...](http://www.showmeai.tech/tutorials/3...)
本文地址:[www.showmeai.tech/article-det...](http://www.showmeai.tech/article-details/146)
声明:版权所有,转载请联系平台与作者并注明出处
收藏ShowMeAI查看更多精彩内容

欢迎大家参加吴恩达老师的深度学习专项课程!这门课程将帮助您掌握深度学习的核心知识和技术。以下是课程的概览:
1. **欢迎** - 课程的开始,介绍课程的目的和目标。
2. **深度学习简介** - 深度学习的基本概念、发展历程及其在机器学习中的应用。
3. **数学预备知识** - 必要的数学基础,如线性代数、概率论等。
4. **神经网络基础** - 神经网络的概念、构建和基本操作。
5. **常见深度学习模型介绍** - 讲解常见的深度学习模型,如卷积神经网络(CNN)、循环神经网络(RNN)以及全连接层等。
6. **优化算法** - 深度学习中的优化方法及其在训练过程中的应用。
7. **特征提取** - 特征提取的重要性及其在图像和文本处理中的应用。
8. **模型评估与选择** - 如何选择和评估深度学习模型,包括交叉验证、混淆矩阵等。
9. **案例研究** - 将所学知识应用于实际问题解决,如图像识别、自然语言处理等。
10. **练习与项目** - 通过完成实践任务加深理解,并有机会进行独立研究或合作开发项目。
这门课程旨在为学习者提供全面的深度学习理论和实践知识,使您能够应用这些技术解决实际问题。希望您能从中获得宝贵的知识和技能。请开始您的深度学习之旅吧!

深度学习改变了传统互联网业务,例如网络搜索和广告。它同时也使得许多新产品和企业以很多方式帮助人们,从获得更好的健康关注。
在医疗领域(读取X光图像)、个性化教育、精准化农业以及自动驾驶等众多方面,深度学习都有着不错的表现。
许多人都想学习这些工具,并将其应用到智能化的应用中去。吴恩达老师的《深度学习专业课程》是一个非常好的资源和学习起点。

人工智能被视为新的生产力。在大约一百年前,电气化改变了各行各业,从交通到制造业、医疗保健乃至通讯领域,如今AI已经带来了巨大的变革。
显然,AI的各个分支中,发展最为迅速的是深度学习。因此目前,深度学习已成为科技世界中的热门技术之一。
以下为吴恩达老师深度学习系列课程,涵盖几门关键课程:
- **深度学习导论(Deep Learning for Humans)**:此课程讲解了深度学习的基础理论和概念,旨在帮助你理解并使用机器学习算法解决实际问题。通过本课程的学习,你可以掌握基本的深度学习技术,并为后续课程打下坚实基础。
- **神经网络构建与训练(Building and Training Neural Networks)**:在这一课程中,我们将深入探讨神经网络的设计、构建和训练方法。这将使你能够熟练地设计适用于各种任务的神经网络模型。
- **深度学习应用(Deep Learning Applications)**:本课程聚焦于深度学习的实际应用领域,包括图像识别、自然语言处理以及推荐系统等,并展示了如何利用深度学习技术解决实际问题。
通过这系列课程的学习,你可以掌握机器学习和深度学习的核心知识,理解和运用这些技术来解决各类复杂问题。

### 2.1 神经网络是什么?
神经网络,也称作人工神经网络或深度学习模型,是一种模拟人脑神经系统处理信息方式的计算技术。它由许多层结构组成,每层都有一个输入和输出节点,这些节点通过权重连接。通过调整这些权重,神经网络可以学会识别特定模式、进行预测或者执行各种任务。
### 2.2 神经网络的基本工作原理
在神经网络中,每个节点(称为神经元)接受来自上一层的信号,并根据一个权重加权和与阈值比较来决定输出。这些权重是通过训练过程逐渐调整的,使得整个网络能够适应输入数据并做出预测。
### 2.3 神经网络的基本结构
神经网络通常由以下几部分组成:
- **输入层**:接收原始数据。
- **隐藏层**:执行处理和变换。
- **输出层**:提供最终结果或决策。
每种层中的节点通过权重连接,并在每个时间步中更新其状态。整个系统会经过多次训练,以最小化误差并提高预测准确性。
### 2.4 神经网络的构建步骤
1. **数据准备与预处理**:将输入数据格式化为神经网络可以接受的形式。
2. **特征工程**:提取和转换原始数据使其更适合模型学习。
3. **选择合适的模型**:根据任务需求选择正确的神经网络架构,如RNN、CNN等。
4. **训练模型**:使用大量标注的数据对模型进行训练,调整权重以最小化误差。
5. **验证与测试**:在独立的测试数据集上评估模型性能,确保其泛化能力强。
### 2.5 神经网络的应用领域
- **自然语言处理 (NLP)**:包括文本分类、情感分析和机器翻译等任务。
- **计算机视觉**:图像识别、目标检测和人脸识别等应用。
- **语音识别**:将语音转换为可理解的文本。
- **推荐系统**:根据用户行为预测商品或服务的需求。
神经网络在这些领域中都展现出强大的能力,通过不断学习和适应数据的变化来提高性能。

### 2.1 房价预测案例
吴恩达老师在课程中以房价预测为例介绍深度学习。假设我们有一个数据集,其中包含六栋房子的信息(房屋面积和房屋价格)。我们的目标是拟合一个函数,基于房屋面积来预测房屋价格。
### 深度学习与神经网络训练
在吴恩达老师的例子中,我们使用深度学习中的神经网络来解决房价预测问题。这涉及到训练神经网络的过程。有时,“深度学习”这个词也会指特别大规模的神经网络训练。
通过这个例子,我们可以看到深度学习不仅仅是处理数据的方法,而且是一种可以应用于各种领域的强大技术。它能帮助我们在许多复杂的问题上找到最优解。
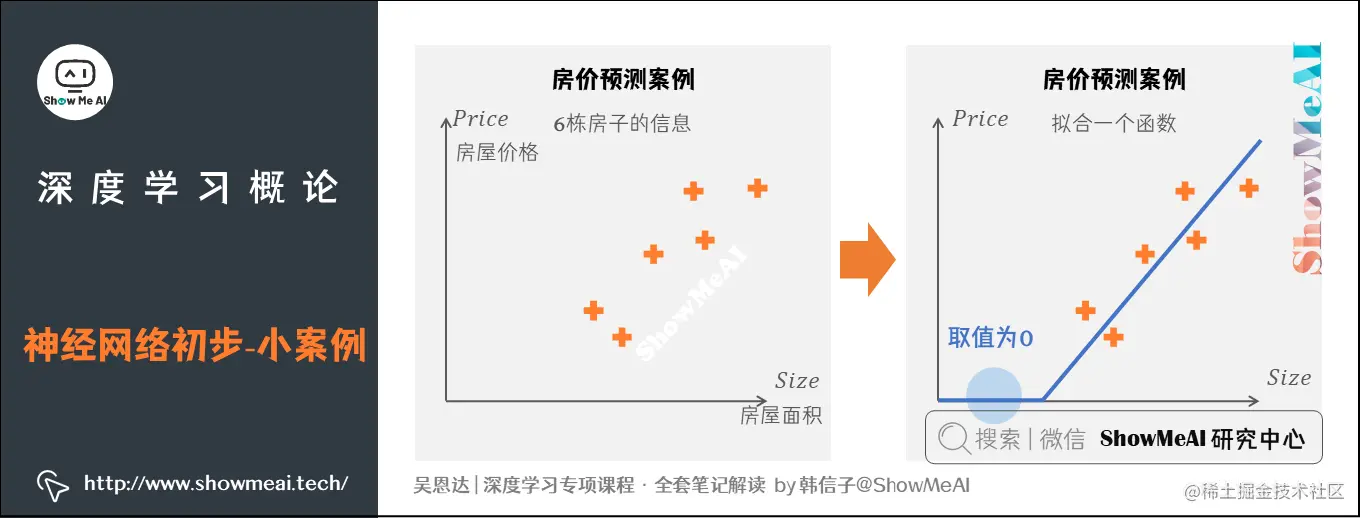
在使用线性回归进行预测时,我们将一条直线调整为略微弯曲的状态,并使其在原点处结束,这样可以更有效地预测房屋价格。这条粗蓝线代表了最终的函数表达式,它基于房屋面积来估计房价。
2.2 ReLU激活函数
为了构建一个神经网络模型,我们从输入(房屋面积)开始,通过一系列节点(小圆圈)计算输出(房屋价格)。每个节点负责处理一部分输入数据,并将它们组合起来形成最终的预测结果。这个过程可以看作是一个单独的神经元,是简单神经网络的基础构成单元。
在上述描述中,我们使用线性回归模型来拟合房价与房屋面积的关系,并通过ReLU激活函数进一步优化了模型的性能。
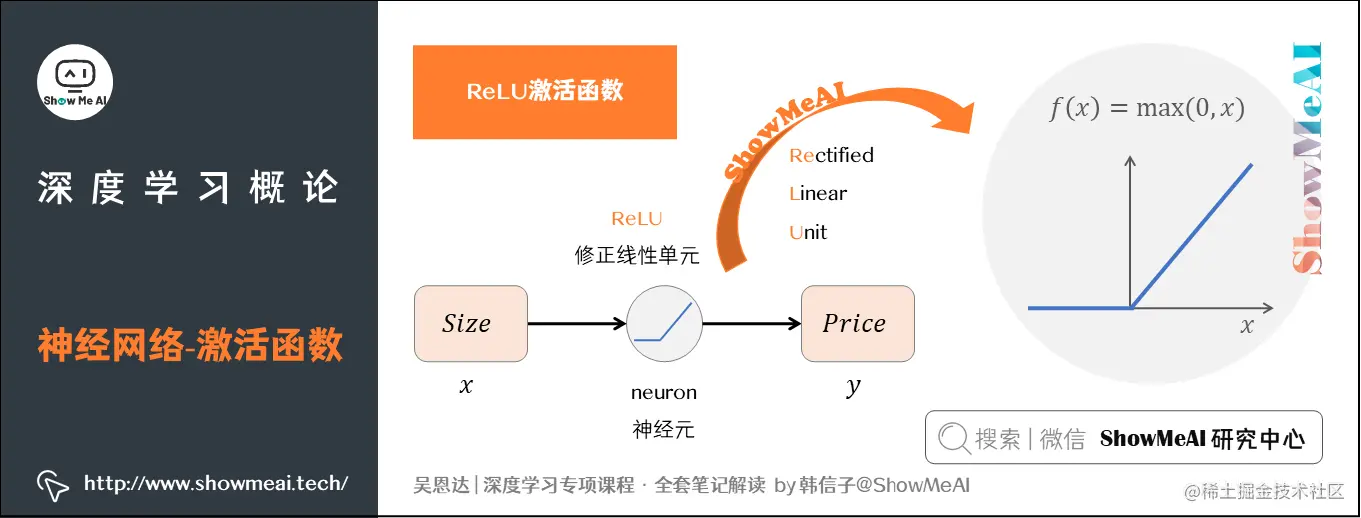
在这个折线表达式就被称作ReLU激活函数,全称为Rectified Linear Unit(修正线性单元),其中rectify(修正)可以理解成f(x)=max(0,x)。在后续的神经网络教程中,大家会频繁地看到这个函数。
上图所示为最简单的神经网络,更复杂的网络可以通过这个结构堆叠得到。你可以把这些神经元想象成单独的乐高积木,通过“搭积木”的方式可以完成一个更复杂的神经网络。
2.3 房价预测案例 <更多特征> 假如问题更复杂一些,我们有房子的信息:
房屋面积(Size)、卧室数量(#Bedrooms)、邮政编码(Zip Code)和周边富裕程度(Wealth)。那么问题升级为下图所示的情况:
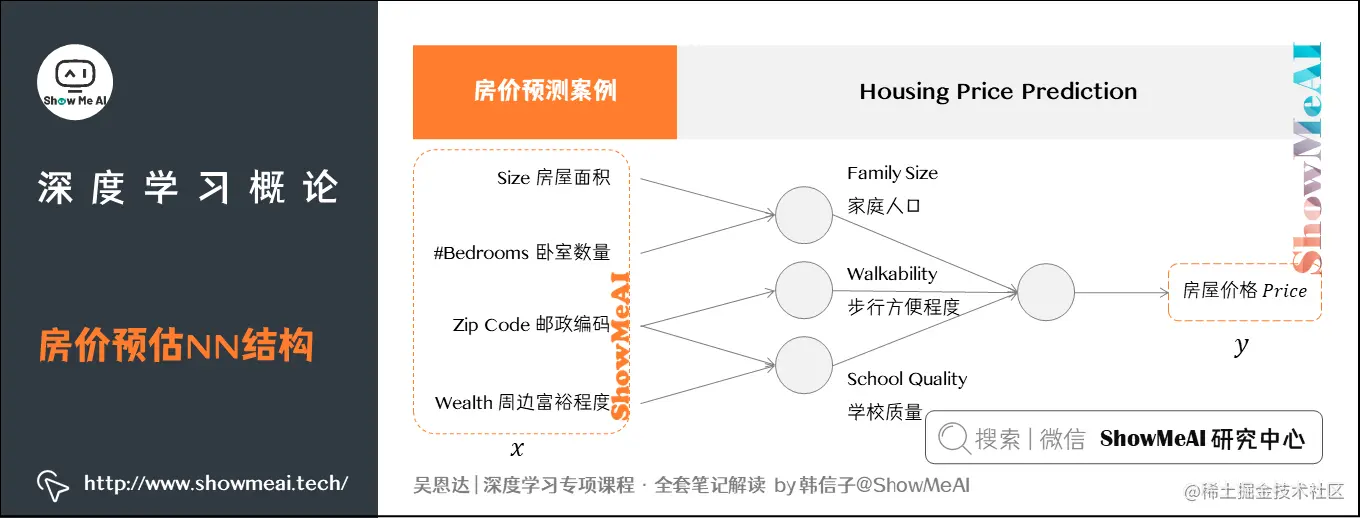
在图中,每一个小圆圈都代表一个ReLU(修正线性单元)或其他非线性函数的一部分。这些ReLU或非线性函数共同作用,使整个网络能够对房屋的价格进行预测。
基于房屋的面积和卧室的数量,我们可以估算出家庭的人口数(Family Size)。
而根据邮政编码,可以评估出行便利程度(Walkability),或者学校的质量(School Quality)。
在实际应用中,这些人口数、出行便利程度以及学校质量都能帮助我们更好地预测房屋的价格。将所有这些特征输入与房价的输出进行组合,就形成了一个稍微大的神经网络模型。
在这个模型中,隐藏单元(图示中的橙色小圆圈)是根据4个输入特征(房屋面积、卧室数量、邮政编码和富裕程度)来获得自身输入的。
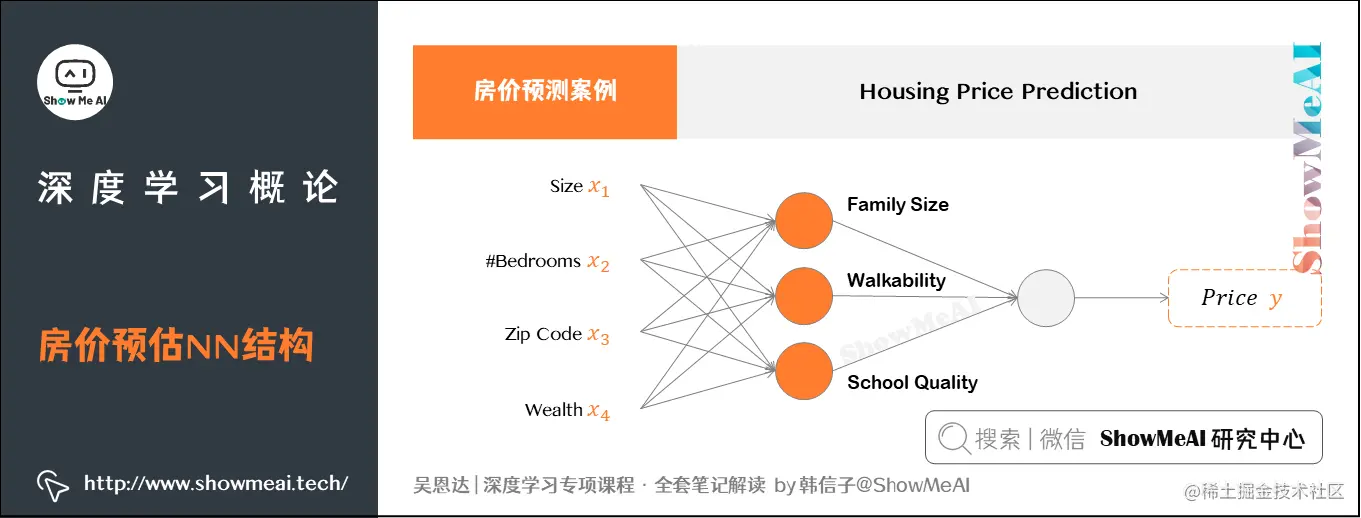
在计算机网络中,第一个橙色节点代表家庭人口。这一节点是由神经网络自己决定的,并不是由x1x_1x1和x2x_2x2这两个变量直接决定的。
当我们提供足够的xxx和yyy数据(即足够的训练样本)时,神经网络能够精准地学习从xxx到yyy之间的映射函数。
3. 使用神经网络进行监督学习(Supervised Learning with Neural Networks)

任务本质上属于监督学习范畴,我们的数据集包含了特征xxx和标签yyy(详见《机器学习基础知识 | 图解机器学习》)。在房价预测的例子中,xxx是房屋特征,yyy则是房屋价格。
同样地,在监督学习方法的驱动下,神经网络结构已经被高效应用于众多领域。如图所示。
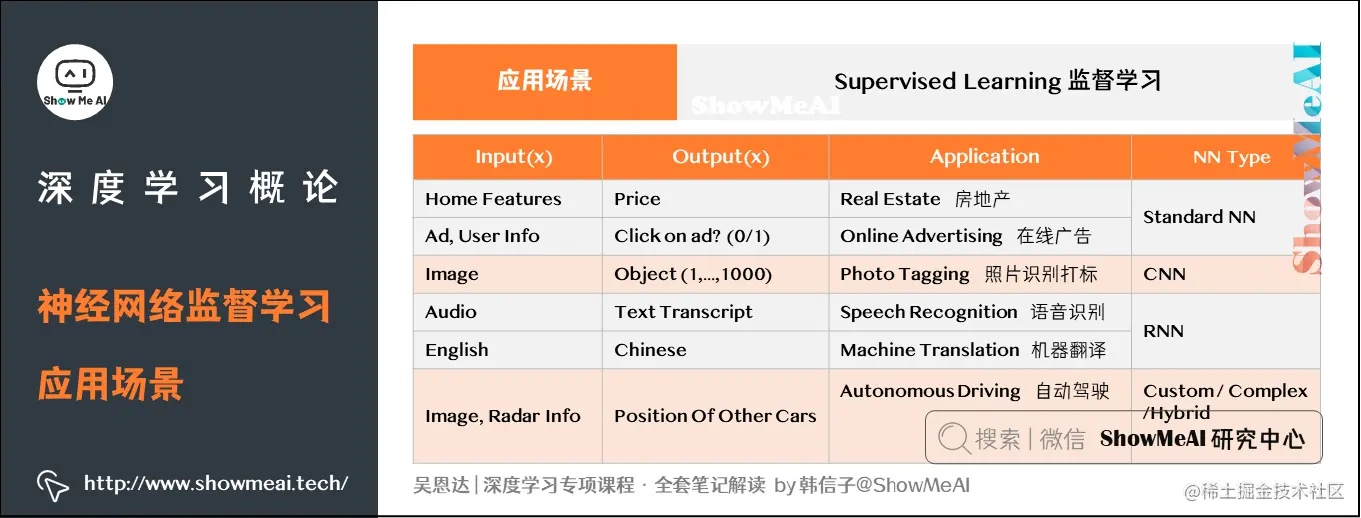
3.1 应用
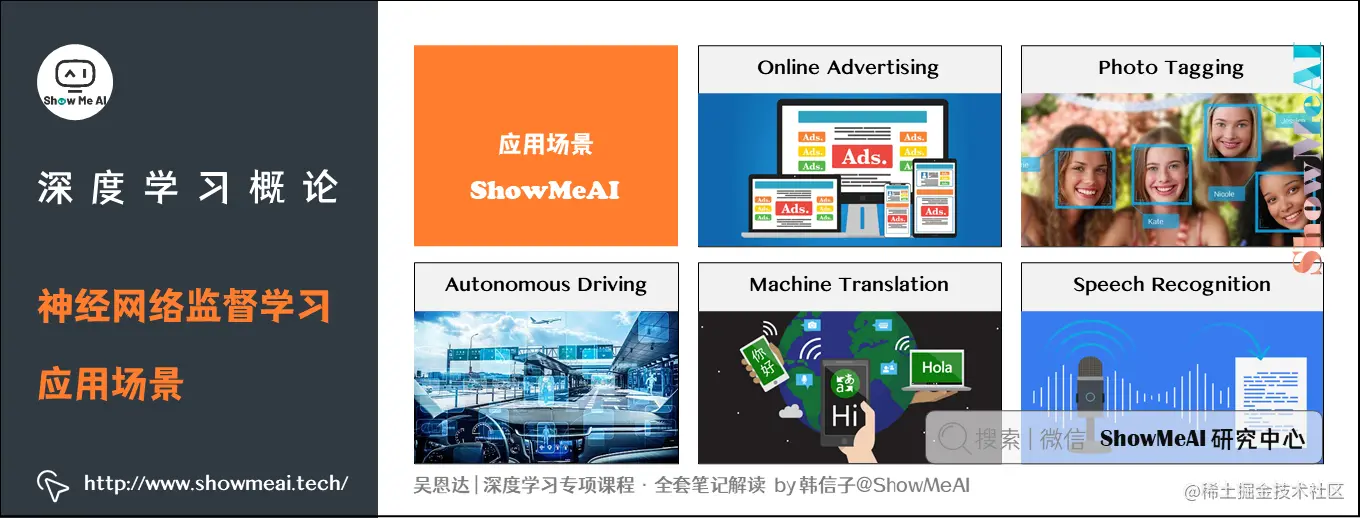
Online Advertising 在线广告
如今应用深度学习获利最多的一个领域,就是在线广告。
神经网络非常擅长预测你是否会点开推荐的网页/视频广告,通过广告与用户信息建模,推荐最有可能点击的广告,进而给大型的在线广告公司带来丰厚的收入。
Photo tagging 照片识别打标
得益于深度学习,计算机视觉在过去的几年里也取得了长足的进步。目前大家的相册照片,可以使用自动标注和智能识别的功能。
Speech recognition 语音识别
深度学习最近在语音识别方面的进步也极其巨大,如今语音识别可以做到很好的一个效果程度,大家日常用的手机语音助手,都是它的典型应用。
Machine translation 机器翻译
得益于深度学习,机器翻译也有很大的发展。如今大家可以轻松地借助于机器翻译,阅读不同语种的信息内容。
Autonomous driving 无人驾驶
未来AI的一个极大应用场景就是自动驾驶技术,可以通过训练一个神经网络,来告诉汽车在马路上面具体的位置,进而帮助自动驾驶系统来判断和控制。
3.2 神经网络的类型
实际神经网络有着不同的结构,而这些典型的结构,也适用于不同的场景,例如:
(1) 对于房地产和在线广告来说,可能是相对标准一些的神经网络(比如全连接的前馈神经网络,或者wide&deep这种组合网络)。
(2) 对于图像应用,我们经常在神经网络上使用卷积(Convolutional Neural Network),通常缩写为CNN。
(3) 对于序列数据(例如音频和文本,含有时间成分),经常使用RNN,一种递归神经网络(Recurrent Neural Network)。
音频随时间播放,所以音频被表示为一维时间序列(one-dimensional time series,或称one-dimensional temporal sequence)
语言(英语的字母或汉语的汉字)都是逐个出现的,所以语言最自然的表达方式也是序列数据,通常此类问题会使用更复杂的RNNs结构。
(4) 对于更复杂的应用(比如自动驾驶),其中的图片任务可以使用CNN卷积神经网络结构。但是雷达信息却需要使用不同的网络结构,这些结构可能是定制的、复杂的或混合的神经网络结构。
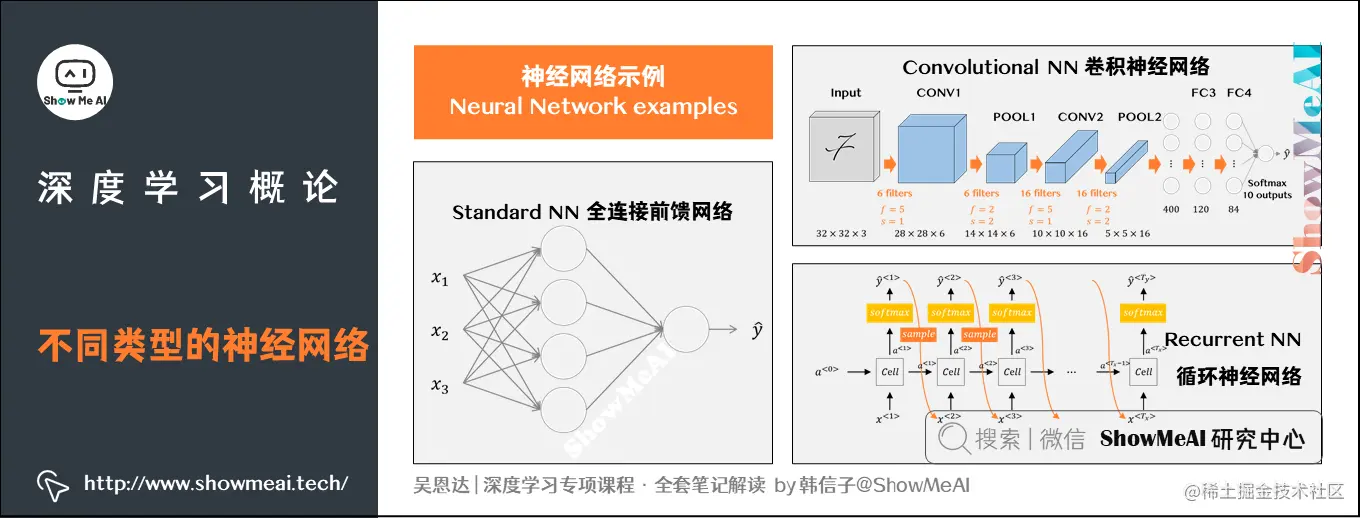
上图左:一个标准的神经网络
上图右上:一个卷积神经网络(CNN),通常用于图像数据
上图右下:循环神经网络(RNN),通常用于序列数据
3.4 结构化数据与非结构化数据
AI算法的有效应用,依赖于数据。我们先对数据做一个了解。
首先,数据可以分为两类:
- 结构化数据
- 非结构化数据
(详见《机器学习实战 | Python机器学习算法应用实践》中对两类数据的不同建模处理方式)
(详见《机器学习实战 | 机器学习特征工程最全解读》中对于结构化和非结构化数据的区分处理)
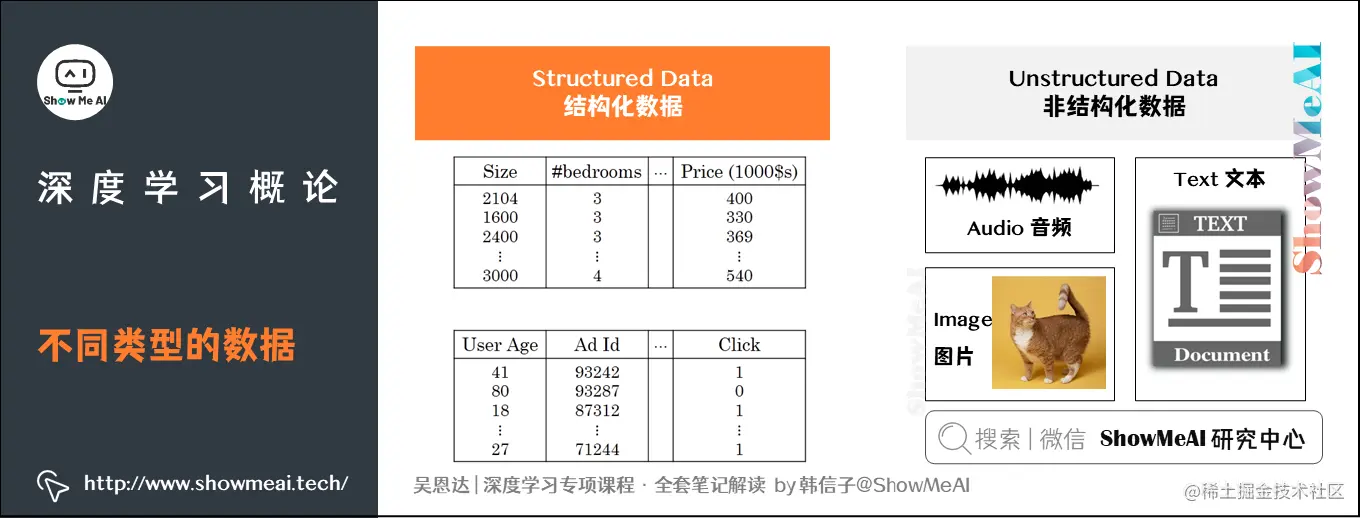
### 结构化数据
结构化数据通常指的是行列表格状的数据,一般存储在数据库中。
例如,在房价预测中,数据库中存储的数据集有几列专门用于指代卧室的大小和数量。这就是结构化数据的例子。
或者,预测用户是否会点击广告时,你可能会得到关于用户的年龄以及广告的一些信息,并进行分类标注。
### 非结构化数据
非结构化数据指的是比如音频、图像或文本等数据内容。这里的原始特征可能是图片中的像素值或文本中的单个单词。处理这类数据是相对较困难的。传统机器学习模型的效果有限,而深度学习神经网络非常擅长解决这一问题。计算机通过神经网络能更好地理解和解释这些非结构化数据。语音识别、图像识别和自然语言处理等领域的应用都有了显著的提升。
### 深度学习兴起的原因
深度学习之所以兴盛,有几个重要原因:
1. **大量数据**:深度学习依赖于大量的训练数据以获得更好的性能。
2. **强大的计算能力**:现代GPU和TPU提供了足够的计算能力来处理大型模型。
3. **模型复杂性和灵活性**:深度网络能够自动进行特征学习,适应不同领域的任务。
4. **领域应用的突破**:从语音识别到图像分类再到自然语言处理等众多应用领域的进展推动了其发展。

推动深度学习变得如此热门的主要因素包括数据规模、计算能力及算法模型的创新。以下是四个关键点:
4.1 为什么深度学习能够如此有效?
4.1.1 数据量的重要性
在图中,横轴表示所有任务的数据量(Amount of Data),而竖轴表示机器学习算法的性能(Performance)。例如,垃圾邮件过滤、广告点击预测和自动驾驶时的位置判断等任务的准确率。
随着数据规模的增长,机器学习模型能够从数据中提取出更多有用的信息。深度学习正是通过大量的训练数据来提高其准确性。这种现象被称为“大样本效应”。
4.1.2 计算能力的提升
除了数据量,计算能力也是深度学习发展的重要因素。随着GPU、TPU等加速器设备的出现,机器学习模型可以更快地完成训练和预测任务。
这使得深度学习算法能够在更短的时间内处理大规模的数据集,并且在更复杂的环境中提供更好的性能。
4.1.3 算法模型的创新
最后,算法模型的创新是推动深度学习发展的关键。近年来,深度神经网络、卷积神经网络和循环神经网络等不同类型的神经网络被广泛应用于各种任务中。
这些创新使得深度学习能够在图像识别、语音识别、自然语言处理等多个领域取得突破性进展,并且在一些挑战性的任务中表现出色。
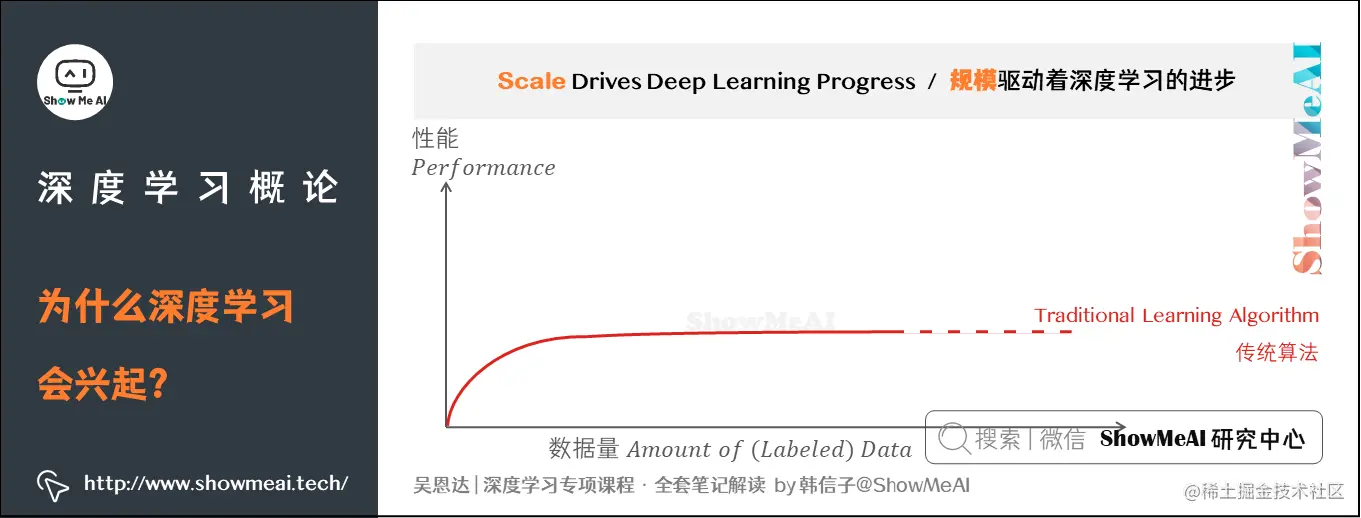
根据图像可以发现,一个传统机器学习算法的性能,作为数据量的函数,是一条曲线。如图所示,一开始,算法性能会随着数据的增多而上升;但一段变化后,它的性能就会达到瓶颈而难以提升。过去十年,我们遇到的很多问题只有相对较少的数据量。
然而,数字化社会带来了巨大的数据量提升。相比于传统机器学习模型,深度学习神经网络更能在海量数据上发挥作用。下图展示的是不同的算法在不同数据规模下的表现。
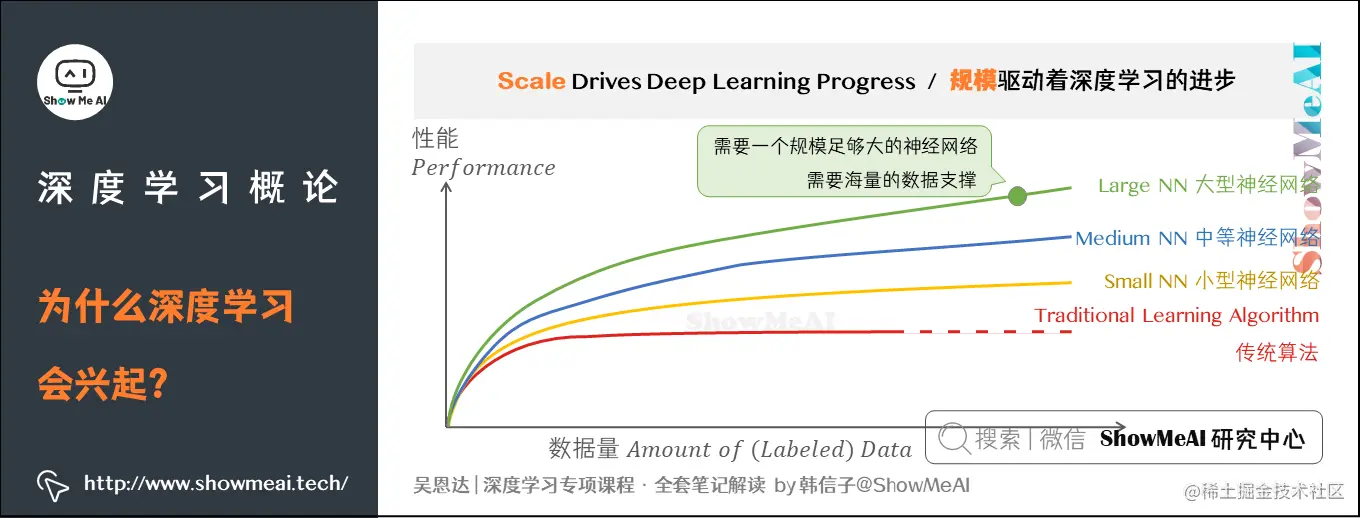
如果你训练一个小型的神经网络(Small NN),性能可能类似于黄色曲线所示;
如果训练中等规模的神经网络(Medium NN),在某些数据上的表现也会更好一些,如蓝色曲线。
而当使用非常大的神经网络(Large NN)时,其性能则会变成绿色曲线,并持续改善。
因此,想要获得橙色点较好的性能,需要满足以下两个条件:
一是训练一个具有足够大规模的神经网络,发挥数据大规模优势;
二是拥有大量数据作为支撑。
我们常提到「规模驱动着深度学习的进步」,这里的「规模」同样指神经网络的规模——我们需要一个包含很多隐藏单元、参数及关联性的大型神经网络。正如需要大量的数据一样。

首先,我们回到上面这个图,在左边(Small Training Sets)区域,各种算法之间的效果优劣并不完全确定。最终的效果很大程度上取决于工程构建特征的能力以及算法处理方面的细节(详见《机器学习实战》中《机器学习特征工程最全解读》)。而在右边(Large Training Sets)区域,随着数据量的增加,大型神经网络通常表现出更好的性能。
在深度学习萌芽初期,数据规模和计算能力(包括CPU和GPU)限制了我们训练特别大的神经网络的能力。无论是在CPU还是GPU上,我们都取得了巨大的进步。然而,在最近几年中,算法方面的创新极大地促进了神经网络的速度。许多新算法尝试提高神经网络的运行速度。
4.2 环境函数转换为ReLU
一个具体的例子是,在神经网络方面的一个巨大突破是从Sigmoid函数转换到ReLU函数。

在过去的深度学习中,我们常使用Sigmoid激活函数来定义神经网络的输出。然而,在这些函数两侧附近的梯度接近零,这导致了学习的速度缓慢,并且难以通过梯度下降算法优化参数。
然而,ReLU(修正线性单元)激活函数可以显著改善这个问题。其主要特点在于负值时梯度为0,这意味着更新权重的速度将更加快速。
这一创新背后的原理是对算法进行的改进,而不是对原始数据本身的处理方法。这使得我们能够通过改变计算环境来加速训练过程,并进一步推动神经网络规模的发展。
在实际应用中,我们的神经网络训练和Sigmoid函数类似:
1. **初始状态**:初始化神经网络参数。
2. **梯度计算**:使用梯度下降算法计算损失函数的导数。
3. **权重更新**:根据计算出的梯度调整网络参数。
4. **反向传播**:将损失从输出层逆向推到输入层,以修正错误。
通过这种方式,我们能够利用ReLU激活函数带来的优化效果,快速地训练更复杂的神经网络。
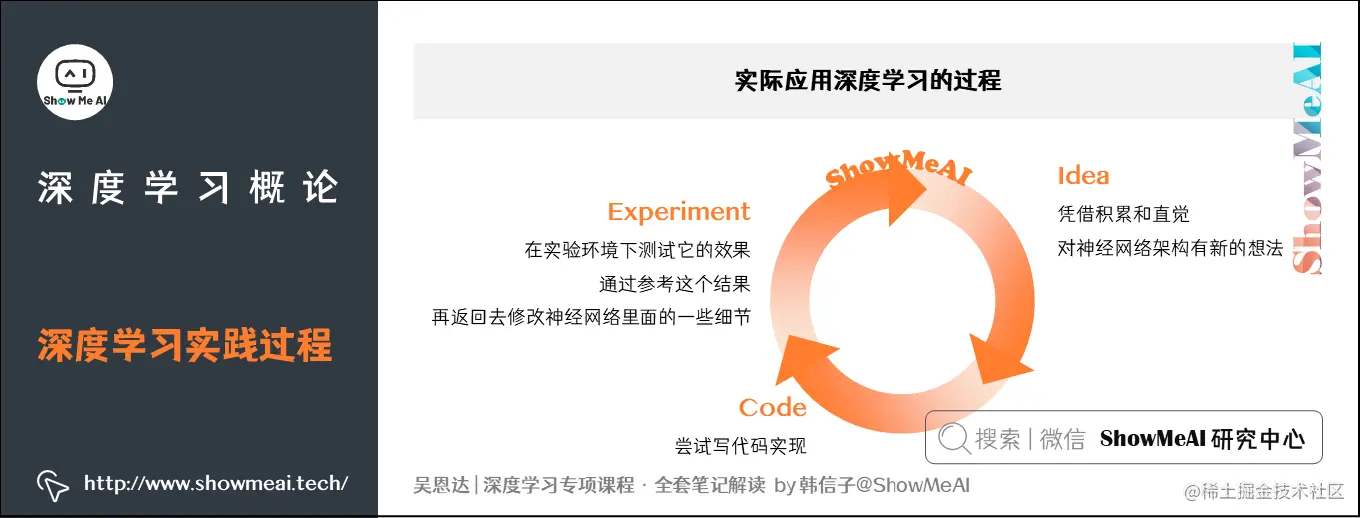
Idea: Develop new ideas for neural network architectures based on experience and intuition.
Code: Attempt to write code to implement these concepts.
Experiment: Test the effectiveness in a simulated environment and iterate back with modifications in your neural network's internals.
We continuously repeat the above steps until we achieve satisfactory results.

吴恩达老师的专项课程包含五门核心内容,当前正在进行第一门课的教学。以下是关于这门课的一些细节:
**第一周:** 介绍深度学习的基础知识。每周的最后都会有一个十多个选择题来检验自己对材料的理解。
**第二周:** 学习神经网络编程的知识,了解其结构,并逐步完善算法,思考如何高效实现。从第二周开始进行一些编程训练(付费项目),自己实现算法。
**第三周:** 在掌握了神经网络编程框架之后,你可以编写一个隐藏层神经网络,因此需要学习所有必要的关键概念来实现神经网络的运作。
**第四周:** 建立深层的神经网络结构。
