AIGC爬虫实战(一)
前言
传统的网络爬虫系统效率较低且难以应对复杂多变的网页环境。针对这一问题,基于人工智能生成的内容(AI-Generated Content, AIGC)技术的智能化爬虫应运而生,它能够显著提升爬虫的自主性和适应性,从而更高效地完成网络数据的采集和分析任务。
本文将通过一系列实战案例,深入探讨AIGC技术在网络爬虫开发中的具体应用。
代码实现
在实践中,我们可以通过以下步骤来构建一个基于AIGC技术的智能化爬虫系统:
1. **需求分析**:明确爬虫的目标、目标网站结构以及需要采集的数据类型。
2. **数据抓取**:利用AIGC生成的内容,编写爬虫脚本以自动访问并抓取所需的数据。这通常涉及使用Web爬虫框架(如Scrapy, Beautiful Soup等)和自然语言处理技术来解析网页内容。
3. **数据存储与分析**:将抓取到的数据存储在一个数据库中,并运用机器学习算法进行数据分析,以提取有价值的信息或模式。
4. **持续改进**:根据实际应用中的反馈和结果,不断优化爬虫系统和数据处理方法。
通过上述步骤,我们可以构建出一个高效、智能的网络爬虫系统,有效地完成各类任务。
首先,我们需要安装 `request-promise` 和 `cheerio` 这两个 Node.js 模块。你可以使用以下命令来安装:
```bash
npm install request-promise
npm install cheerio
```
接下来,我们将编写一些代码来爬取豆瓣电影Top250列表。
### 引入所需的Node.js模块
我们首先需要引入这些模块:
```javascript
const rp = require('request-promise'); // 需要安装
const $ = require('cheerio'); // 需要安装
```
### 定义基础URL
定义我们要爬取的 URL,这里我们使用豆瓣电影Top250列表页的 URL:
```javascript
let basicUrl = 'https://movie.douban.com/top250';
```
### 定义getMovieInfo函数
这个函数用于解析 HTML 节点并提取所需数据。它接受一个 HTML 节点作为参数,并返回一个对象,其中包含电影的标题、信息和评分。
```javascript
function getMovieInfo(node) {
let $ = cheerio.load(node);
let titles = $('.info .hd span');
titles = [].map.call(titles, t => $(t).text());
let bd = $('.info .bd');
let info = bd.find('p').text();
let score = bd.find('.star .rating_num').text().split('/')[0]; // 分成两段取前一段,豆瓣评分格式为XX.X
return { titles, info, score };
}
```
### 定义getPage函数
这个函数接受一个 URL 和页码作为参数。它使用 `request-promise` 发送 HTTP 请求获取页面内容,并使用 `cheerio` 解析页面,提取每部电影的信息。
```javascript
async function getPage(url) {
let html = await rp(url);
console.log(`连接成功!正在爬取第1页数据`);
let $ = cheerio.load(html);
let movieNodes = $('#content .article .grid_view').find('.item');
let movieList = ([]).map.call(movieNodes, node => {
return getMovieInfo(node);
});
return movieList;
}
```
### 定义main函数
这个函数为程序入口点,设置需要爬取的页数并调用 `getPage` 函数获取数据。
```javascript
let count = 25; // 爬取25页(共250部电影)
async function main() {
let list = [];
for (let i = 0; i < count; i++) {
let url = basicUrl + `?start=${25 * i}`;
list.push(...await getPage(url));
}
console.log(`所有页面数据已合并完毕`);
fs.writeFile('./output.json', JSON.stringify(list), 'utf-8', () => {
console.log('生成json文件成功!');
});
}
main();
```
### 最后,运行代码
确保安装了 `request-promise` 和 `cheerio` 模块。然后使用以下命令运行代码:
```bash
node your_script.js // 请将 'your_script.js' 替换为你的实际文件名
```
这将爬取豆瓣电影Top250列表,并将数据保存到一个 JSON 文件中。
通过这种方式,你可以轻松地从网页上抓取所需的信息,然后将其存储在本地或发送给服务器进行进一步处理。
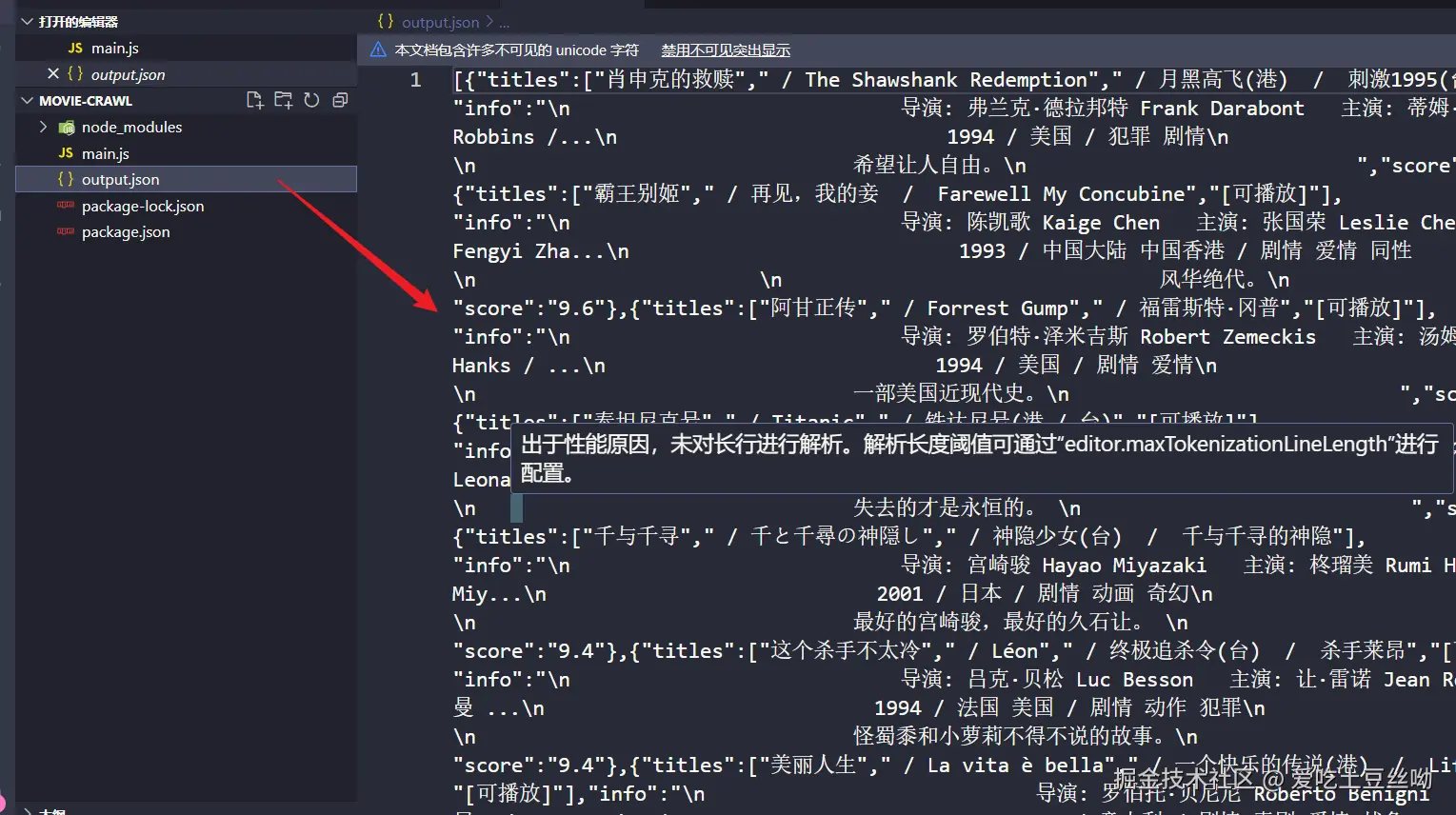
我们发现当前的数据格式存在一些问题。
接下来,我将把第一个数据传递给AI进行处理。
可以这样改写:
目前的数据格式存在问题。
首先,我会将第一个数据提交给AI处理。
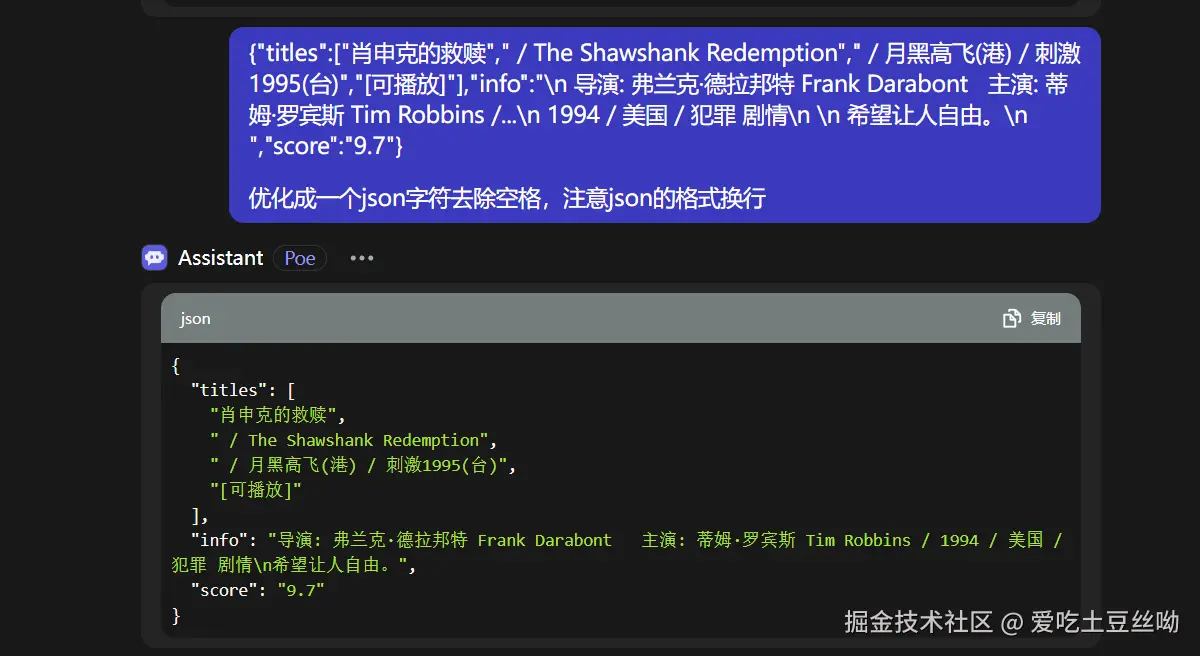
可以看到AI对我们处理数据的效果不错,所以AI能有效地提高我们爬取数据的效率。
下篇文章我们将讲解如何调用AI的API来快捷地处理数据。
总结
本文将通过实战案例深入探讨AIGC技术在网络爬虫开发中的应用。基于AIGC技术的智能化爬虫可以大幅提升爬虫的自主性和适应性,从而更高效地完成网络数据的采集和分析任务。AI在项目中的大力使用能够有效提升项目的整体能力。